
Abstract
Representing wild sounds as images is an important but challenging task due to the lack of paired datasets between sound and images and the significant differences in the characteristics of these two modalities. Previous studies have focused on generating images from sound in limited categories or music. In this paper, we propose a novel approach to generate images from in-the-wild sounds. First, we convert sound into text using audio captioning. Second, we propose audio attention and sentence attention to represent the rich characteristics of sound and visualize the sound. Lastly, we propose a direct sound optimization with CLIPscore and AudioCLIP and generate images with a diffusion-based model. In experiments, it shows that our model is able to generate high quality images from wild sounds and outperforms baselines in both quantitative and qualitative evaluations on wild audio datasets.
Method Overview
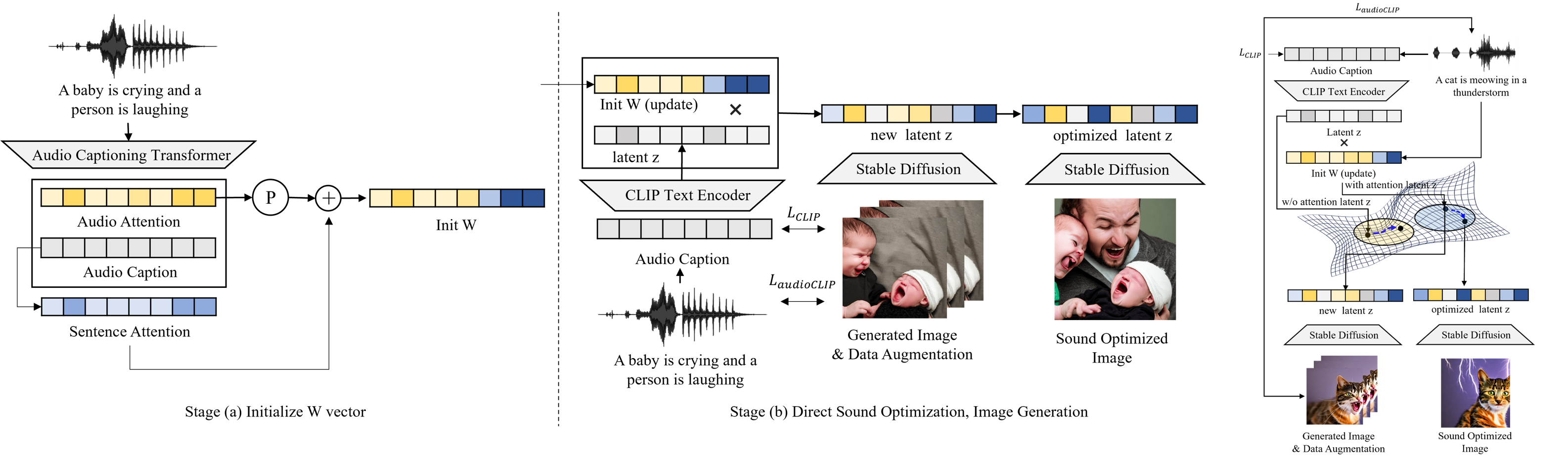
Overall architecture of our model. Our model consists of two stages. Stage (a) is the step of initializing the W vector with attentions, and Stage (b) is direct sound optimization and image generation process. Process of direct sound optimization. When initializing latent z with attentions, we optimize in the blue area, whereas without using attention, we optimize in the yellow area. To solve the problem of local minimum and to represent the rich features of sound, attentions are necessary.
In-the-wild Sound to Image Results

A crowd applauds for a while

Ocean waves crashing as water trickles and splashes

Motorcycle starting then driving away

A motorboat accelerating and water splashing

Birds chirping and bees buzzing

A main horn honks, a train passes by

Continuous gunshots, a man grunts and more gunshots

Rustling followed by a man speaking and a child laughing

Rain falling and dripping from a roof, then thunder rolls

A man is speaking as paper is crumpling
In-the-wild Sound to Image Results, Multi-ESC50

A cat is meowing in the thunderstorm

A woman is laughing and a dog is barking

A dog is barking in the rain

a helicopter is flying in the rain

Birds are chirping in the thunderstorm
BibTeX
@inproceedings{lee2023generating,
title={Generating Realistic Images from In-the-wild Sounds},
author={Lee, Taegyeong and Kang, Jeonghun and Kim, Hyeonyu and Kim, Taehwan},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={7160--7170},
year={2023}
}Acknowledgment
This work was partly supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.2022-0-00608, Artificial intelligence research about multi-modal interactions for empathetic conversations with humans & No.2020-0-01336, Artificial Intelligence Graduate School Program (UNIST)) and the Settlement Research Fund (1.210147.01) of UNIST (Ulsan National Institute of Science & Technology).