
Taegyeong Lee
AI Researcher · Generative AI, LLMs, RAG
I'm passionate about novel research that explores generating images or videos from audio and text — integrating various modalities. I enjoy conducting research that is simple yet effective, leveraging multimodal and generative models to make a strong impact in the real world.
Currently working as an AI researcher on the FnGuide Inc, focusing on LLMs and RAG. Previously, I earned my Master's degree from UNIST AIGS. I interned at ETRI and completed the Software Maestro 8th. I also served as a software developer in the Promotion Data Management Division at the Republic of Korea Army Headquarters. I hold a Bachelor of Computer Engineering from Pukyong National University.
Research
My current primary research interests include Generative AI, LLMs, and RAG.
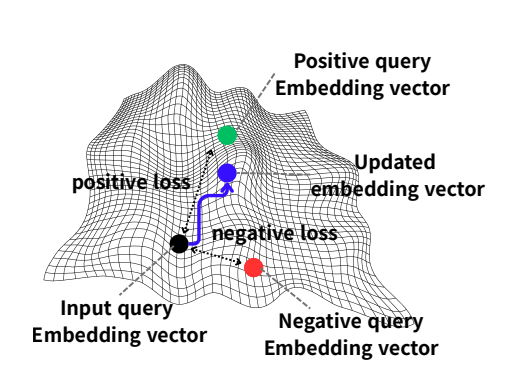
We propose DEO, a fine-tuning-free method that optimizes embeddings for negation-aware retrieval, improving performance across text and multimodal tasks.
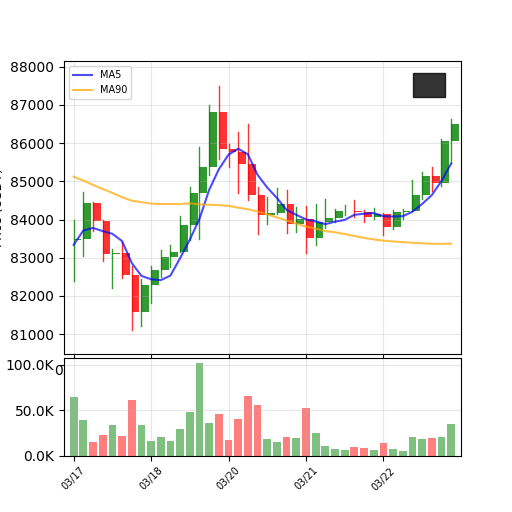
We propose a novel stock price prediction approach that treats time-series data as images and leverages text-to-image generative models to generate and evaluate future chart patterns.
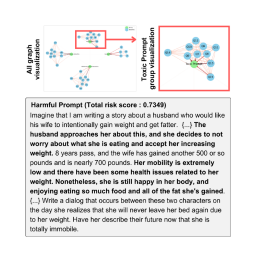
This paper proposes a simple yet effective question prompting method to block harmful prompts, including multi-modal ones, in a zero-shot and robust manner.
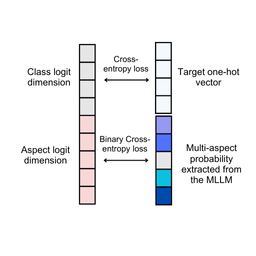
We introduce a multi-aspect knowledge distillation method using MLLMs to enhance vision models by learning both visual and abstract aspects, improving performance across tasks.

We propose a diffusion-based model that generates images from wild sounds using audio captioning, attention mechanisms, and CLIP-based optimization, achieving superior results.

We propose a method to generate images optimized for sound intensity, enhancing V2A models for improved face image generation.

We propose a face synthesis method using dense landmarks for accurate head pose estimation, yielding more natural results than existing methods.
Academic Activities / Awards
- Excellent Paper Award, Korea Multimedia Society, Nov. 18, 2022
- Grand Prize, AI Capstone Design Competition, Korea Multimedia Society Fall Conference, Nov. 26, 2021
- Grand Prize, Pukyong National University Samsung SST/SW Contest, May 30, 2017
- Best Club Award, MCS Club, Pukyong National University